- 首页
- 知识管理
-
知识智能
-
知识智能产品
-
-
能够处理复杂的语言结构和上下文关系,生成准确、连贯的文本。可以帮助人们提高工作效率,减轻写作负担,节省时间精力。可以为创造性的内容生成提供参考支持。
-
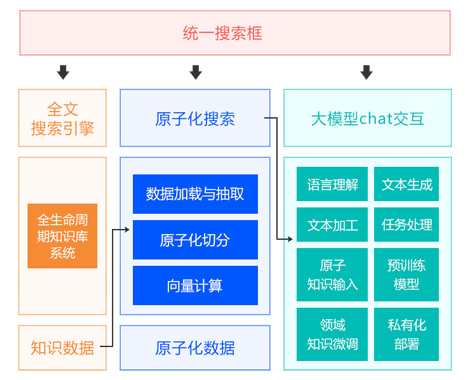
深蓝海域知识中台是一款领先的企业级知识内容及相关技术能力的复用知识管理平台,
通过智能化的技术和全面的功能模块,帮助企业高效管理、共享和应用知识。 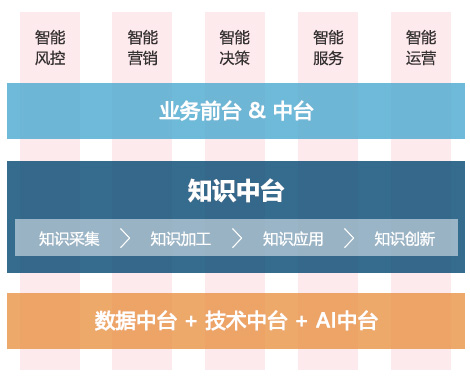
-
智慧云搜索平台,可解决企业搜索需求的同时降低系统开发成本,统一各类数据呈现等。
有效的提升知识共享的内容质量。 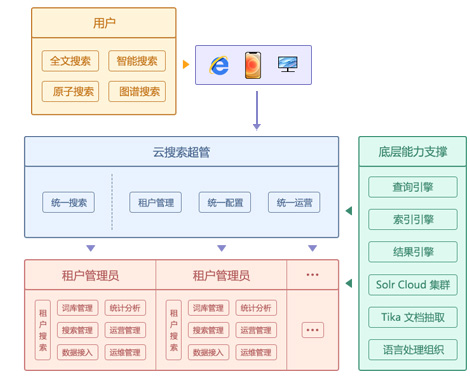
-
全智能知识库构建了一套涵盖智能知识采集、加工、理解、应用全流程的智能知识库系统。
基于AI技术和算法,实现爬虫采集、模型萃取等5+智能化的知识采集工具,自动标签、抽取FAQ等10+智能知识加工能力,语义和图像识别等6+智能知识理解引擎,以及智能搜索、智能问答等7+知识智能应用场景和方案。 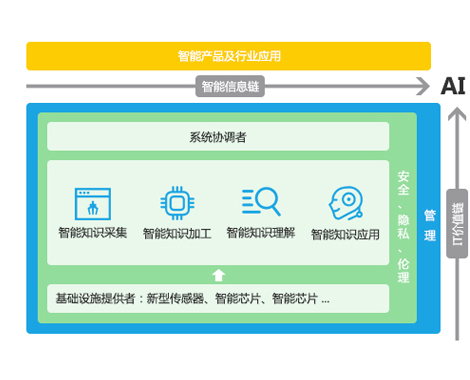
-
在知识库中,仅仅通过数据库检索,全文搜索,往往会出现搜索不到、搜索不准的情况。
深蓝海域运用人工智能技术,探索搜索引擎的智能化,让用户搜索知识变动更简单 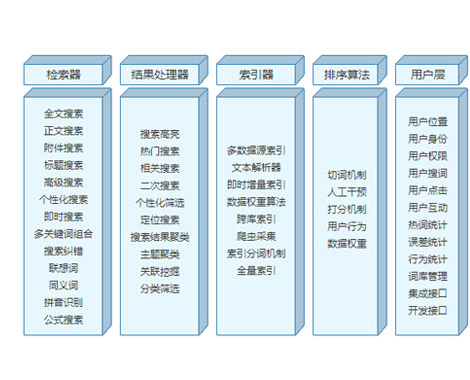
-
如果您每天花大量的时间在指定的网站上查找各类知识信息,作为研究、内参,如果您正在苦恼这些信息需要人工下载,需要人工辨别分类,需要人工去重,去干扰,那您不能错过“包打听”。
基于爬虫和机器学习技术打造,自动采集、自动去重归类、个性化分发推荐、知识关联挖掘,为您打听您想了解的内容! 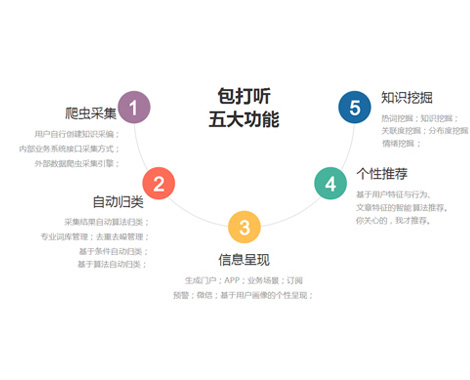
-
工单系统中具有海量数据的工单信息,通过构建和训练“工单知识萃取模型”,萃取出有效的工单知识,将其应用于工单的提出、处置等环节,从而减少重复工单的提出率、提升工单处置效率和解决准确率。

-
原子化智能搜索引擎是深蓝海域基于智能语义算法、原子化引擎技术开发的创新搜索技术。
对用户输入关键词自动进行语义算法处理,搜索更合理的结果,而非简单的词语匹配;搜索结果只显示最匹配的文章段落,而非将整篇文档呈现给用户。
篇章级内容通过原子化处理,可直接提供原子化知识给问答机器人,大大减少FAQ整理工作量。 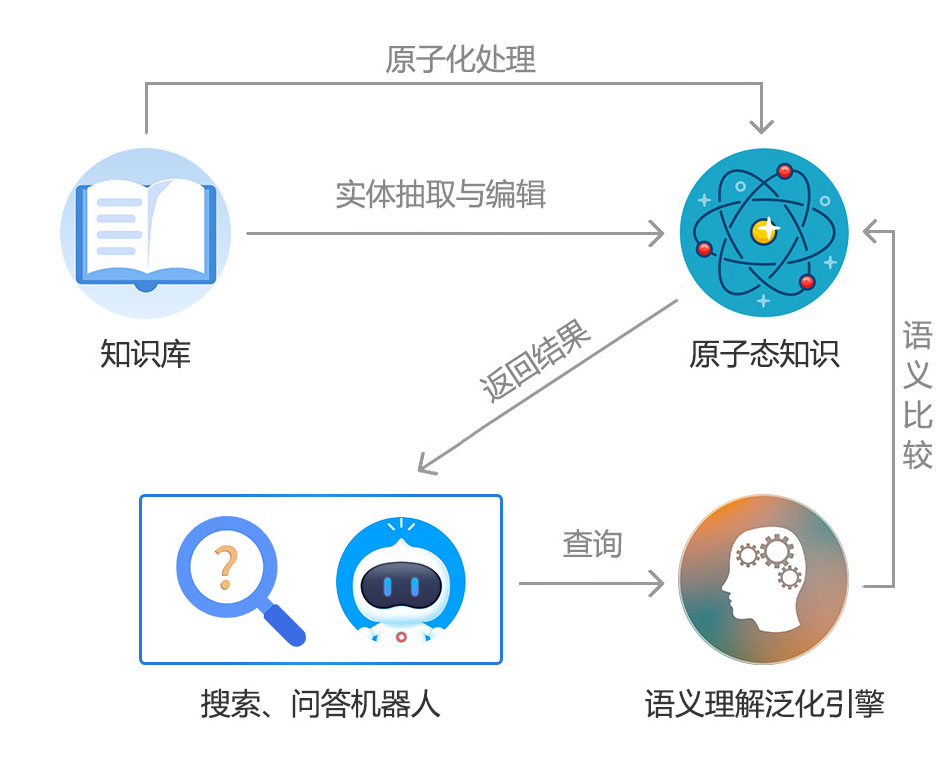
-
-
- 智能问答
- 咨询服务
- 行业案例
- 产品理念
- KM百科
- 关于我们
 2007-11-12 14:19
2007-11-12 14:19