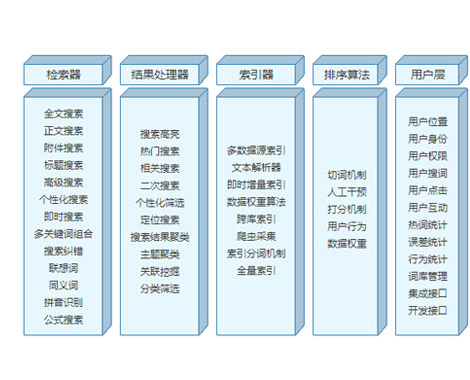
一 数据过剩与知识贫乏
计算机与信息技术经历了半个世纪的发展,给人类社会带来了巨大的变化与影响。支配人类社会三大要素(能源 材料和信息)中,信息愈来愈显示出其重要性和支配力,它将人类社会由工业化时代推向信息化時代,使现代社会所有大的机构都卷入到以数据及其处理(数据搜集 存储 检索 传送 分析和表示)的浪潮中。而随着人类活动范围扩展,节奏加快,以及技术的进步,人们能以更快速较易而廉价的方式获取和存储数据,这就使得数据和信息量以指数形式向上增长。早在八十年代,人们粗略地估算到全球信息量,每隔20个月就增加班一倍。进入九十年代,各类机构所有数据库数据量增长更快。一个不大的企业每天要产生100MB以上来自各方面的营业数据。美国政府部门的一个典型的大数据库每天要接收约5TP数据量,在15秒到1分钟时间里,要维持的数据量达到300TB,存档数据达15-100PB。在科研方面,以美国宇航局的数据库为例,每天从卫星下载的数据量就达3-4TB之多,而为了研究的需要,这些数据要保存七年之久。九十年代因特网(Internet)的出现和发展,以及随之而来的企业内部网(Intranet)和企业外部网(Extranet)以及虚拟私有网(VPN--Virtual Private network)的产生和应用,将整个世界联成一个小小的地球村,人们可以跨越时空地在网上交换信息和协同工作。这样,展现在人们面前的已不是局限于本部门,本单位和本行业的庞大数据库,而是浩瀚无垠的信息海洋。据估计,1993年面全球数据存贮容量约为二千TP,到达2000年会增加到三百万TB,对这极度膨胀的数据信息量,人们受到“信息爆炸”“混沌信息空间”(Information Chaotic Spact)和“数据过剩”(Data glut)的巨大压力。
然而,人类的各项活动基于人类的智慧和知识,即对外部世界的观察和了解,正确的判断和决策以及采取正确的行动,而数据仅仅是人们用各种工具和手段观察外部世界所得到的原始材料,它本身没有任何意义。从数据到智慧,要经过分析加工处理精炼的过程。如图1所示:数据是原材料,它只是描述发生了什么事情,它不提供判断或解释,和行动的可靠基础。人们对数据进行分析找出其中关系,赋予数据以某种意义和关联,这就形成所谓信息。信息虽给出了数据中一些有一定意义的东西,但它往往和人们手上的任务没有什么关联,还不能做为判断 决策和行动的依据。对信息进行再加工,进行深入洞察,才能获得更有用可资利用的信息,即知识.所谓知识,可以定义为“信息块中的一组逻辑联系,其关系是通过上下文或过程的贴近度发现的。”从信息中理解其模式,即形成知识。在大量知识积累基础上,总结成原理和法则,就形成所谓智慧(Wisdom).其实,一部分人类文明发展史,就是在各种活动中 知识的创造 交流 再创造不断积累的螺旋式上升的历史。另一方面,计算机与信息技术的发展,加速了这种过程,据德国世界报的资料分析,如果说19世纪时科学定律(包括新的化学分子式,新的物理关系和新的医学认识)的认识数量一百年增长一倍,到本世纪60年代中期以后,每五年就增加一倍。这其中知识起着关键的作用。当数据量极度增长时,如果没有有效的方法,由计算机及信息技术来提取有用信息和知识,也感到像大海捞针一样束手无策。据估计,一个大型企业数据库中数据,只有百分之七得到很好应用.这样,相对于“数据过剩” 和“信息爆炸”,人们又感到“信息贫乏”(Information poor)"数据关在牢笼中”(data in jail).
二 从数据到知识
早在八十年代,人们从“物竞天择 适者生存”的大原则下,认识到“谁最先从外部世界获得有用信息并加以利用谁就是优胜者”。现时当市场经济面向全球性剧烈竞争的环境下,一家厂商的优势不在于像产品 服务 地区等方面因素,而在于创新。用知识来作为创新的原动力,就能使公司长期持续保持竞争优势。因此要能及时迅速从日积月累的庞大的数据库及网络上获取有关经营决策有关知识,这是应付客户需求易变性及市场快速变化引起竞争激烈局面的唯一武器。
针对上述情况,如何对数据与信息快速有效地进行分析加工提炼以获取所需知识并发挥其作用,向计算机和信息技术领域提出了新的挑战。其实计算机和信息技术发展的过程,也是数据和信息加工手段不断更新和改善的过程。早年受技术条件限制,一般用人工方法进行统计分析,和用批处理程序进行汇总和提出报告.在当时市场情况下,月度和季度报告已能满足决策所需信息要求。随着数据量的增长,多渠道数据源带来各种数据格式的不相容性,为了便于获得决策所需信息,就有必要将整个机构内的数据以统一形式集成存储在一起,这就是所谓数据仓库(data Warehousing).它不同于只适用于日常工作的数据库.它是为了便于分析针对一定主题(Subject-oriented)的集成化的 时变的(time-Variant即提供存贮5-10或更老的数据,这些数据不再更新,供比较以求出趋向及预测用)非破坏性(即只容易输入和访问不容许更新和改变)的数据集中场所。数据仓库的出现,为更深入对数据进行分析提供了条件,针对市场变化的加速人们提出了能实时分析和报表的在线分析手段OLAP(On Line Analytical Processing),它是一种友好而灵活的工具,它能允许用户以交互方式浏览数据仓库对其中数据进行多维分析,能及时地从变化和不太完整的数据中提出与企业经营动作有关的信息。例如能对数据中的异常和变化行为进行了解,OLAP是数据分析手段的一大进步,以往的分析工具所得到的报告结果能回答“什么”(What),而OLAP的分析结果能回答“为什么”(Why)。但上述分析手段是建立在用户对深藏在数据中的某种知识有预感和假设的前提下。而由于数据仓库(通常数据贮藏量以TB计)及联网界面上的数据来源于多种信息源,因此其中埋藏着丰富的不为用户所知的有用信息和知识,而要使企业能及时迅速准确地作出经营动作的决策,以适应变化迅速的市场环境,就需要有一种基于计算机与信息技术的智能化自动工具,来发掘埋藏在数据中的各类知识。这种手段不应再基于用户假设,而应能自身生成多种多种假设,再用数据仓库或联网的数据进行检验和验证,然后返回对用户 最有用的结果。同时这种工具还应能适应现实世界中数据的多种特性(即量大 含噪声 不完整 动态 稀疏性 异质 非线性等)。要达到上述要求,只借助于一般数学分析和算法是无能为力的。多年来,数理统计技术以及人工智能和知识工程等领域的研究成果,诸如推理 归纳学习 机器学习 知识获取 模糊理论 神经元网络 进化算法 模式识别 粗糙集理论等等分支给开发上述工具提供了坚实而丰富的理论和技术基础。九十年代中期以来,许多软件开发商,基于上述技术和市场需求,开发了名目繁多的数据发掘(DM--Data Mining)和知识发现(KDD--Discovery from Data)工具和软件,DM和KDD形成了近年来软件开发市场的热点,并且已不断出现成套软件和系统,并开始朝智能化整体解决方案发展,这是从数据到知识前进过程中又一个里程碑。
从数据中获取有用信息或知识,是一个完整的对数据进行加工 处理的过程。如图3所示,其中DM是关键的一步。[1]挑选:按一定的标准从数据源中挑选或切取一组数据,形成目标数据。[2]净化和预处理:将不必要或影响分析进程的部分数据删去。[3]转换:将预处理后的数据进行某些转换使之成为可用和可导引的数据。[4]数据发掘:这是关键的阶段,从数据中抽取出信息的模式。所谓模式,可以作如下定义:给定一组事实(数据)F,一种语言L,和某种可信度测量C,模式就是一种用L的描述方式S,它以可信度C对F的一个子集Fs各事实间的关系进行描述,这种描述在某种意义上比枚举Fs中所有事实上要简单得多。[5]解释赋义或可视化:将模式解释为可以支持决策的知识,例如预测 分类 汇总数据内容和解释所观察到的现象等。上述阶段之间也许还需要某种迭代分析.(见图3)从上述过程可以看出,从数据中获取知识是涉及多个领域内技术融合的综合应用。
三 KDD(DM)的任务技术和应用
利用DM(KDD)技术可以完成多项决策所需任务,但大致可分为下述几方面:[1]预测:从事例中求得模式,构造模型以预测目标度量。[2]分类:找出一函数能使每事例映射到某种离散类别之一。[3]查出关系:搜索到对某选定目标变量最有影响的其它独立变量。[4]显式模型:找出描述不同变量间依赖关系的显式公式。[5]聚类:认定出描述数据的类别的有限分组。[6]偏离检测:从数据已有或期望值中找出某些关键测度显著的变化。
由于上述任务的不同,就需要采用不同的技术方法和手段,因而在市面也出现种类繁多的商品工具和软件。大致可以归纳为下列主要类型:
[1]传统主观导向系统:这是针对专业领域应用的系统。如基于技术分析方法对金融市场进行分析。采用的方法从简单的走向分析直到基于高深数学基础的分形理论和谱分析。这种技术需要有经验模型为前提.属于这类商品有美国的Metastak,SuperCharts,Candlestick Forecaster 和Wall Street Money等。
[2]传统统计分析:这类技术包括相关分析 回归分析及因子分析等。一般先由用户提供假设,再由系统利用数据进行验证。缺点是需经培训后才能使用,同时在数据探索过程中,用户需要重复进行一系列操作。属于这类商品有美国的SAS,SPSS和Stargraphis等。由于近年来更先进的DM方法的出现和使用,这些厂商在原有系统中综合一些DM部件,以获得更完善的功能。
以上两种技术主要基于传统的数理统计等数学的基础上,一般早已开始用于数据分析方面。
[3]神经元网络(NN)技术:神经元网络技术是属于软计算(Soft Computing)领域内一种重要方法,它是多年来科研人员进行人脑神经学习机能模拟的成果,已成功地应用于各工业部门。在DM(KDD)的应用方面,当需要复杂或不精确数据中导出概念和确定走向比较困难时,利用神经网络技术特别有效。经过训练后的NN可以想像具有某种专门知识的“专家”,因此可以像人一样从经验中学习。NN有多种结构,但最常用的是多层BP(back propagation)模型。它已广泛地应用于各种DM(KDD)工具和软件中。有些是以NN为主导技术,例如俄罗斯的PolyAnalyst,美国的BrainMaker,Neurosell和OWL等。NN技术也已广泛地做为一种方法嵌入各种DM成套软件中。其缺点是用它来分析复杂的系统诸如金融市场,NN就需要复杂的结构为数众多神经元以及连接数,从而使现有的事例数(不同的纪录数)无法满足训练的需要。另外由受训后的NN所代表的预测模型的非透明性也是其缺点,尽管如此,它还是广泛而成功地为各种金融应用分析系统所采用。
[4]决策树:在知识工程领域,决策树是一种简单的知识表示方法,它将事例逐步分类成代表不同的类别。由于分类规则是比较直观的,因而比较易于理解,虽然在机器获取领域内,多年来已研制出不少实施决策树的有效算法(如ID3及其改进算法等)。但这种方法限于分类任务。在系统中采用这种方法的有美国的IDIS,法国的SIPINA。英国的Clementinc和澳大利亚的C5.0。
[5]进化式程序设计(Evolutionary programming):这种方法的独特思路是:系统自动生成有关目标变量对其他多种变量依赖关系的务种假设,并形成以内部编程语言表示的程序。内部程序(假设)的产生过程是进化式的,类似于遗传算法过程。当系统找到较好地描述依赖关系的一个假设时,就对这程序进行各种不同的微小修正,生成子程序组,再在其中选择能更好地改进预测精度的子程序,如此依次进行,最后获得达到所需精度的最好程序时,由系统的专有模块将所找到的依赖关系由内部语言形式转换成易于为人们理解的显式形式,如数学公式,预测表等。由于采用通用编程语言,这种主法在原则上能保证任何一种依赖关系和算法都能用这种语言来描述。这种方法也许是目前最年青的和最有前途的DN方法之一。这种是方法的商用产品还只见诸俄罗斯的Poly Analyst,据报导,它用于金融到医疗方面军的各种应用于,能获得者很好的结果。
[6]基于事例的推理方法(CBR棗Case based reasoning)这种方法的思路非常简单,当预测未来情况或进行正确决策时,系统寻找与现有情况相类似的事例,并选择最佳的相同的解决方案,这种方法能用于很多问题求解,并获得好的结果,其缺点是系统不能生成汇总过去经验的模块或规则。采用这种方法的系统有美国的Pattern Recognition Workbench和法国的KATE tools.
[7]遗传算法(GA棗Genetic Algorithms):严格说来,DA不是GA应用的主要领域,它是解决各种组合或优化问题的强有力的手段,但它在现代标准仪器表中也用来完成DA任务。这种方法的不足之处是:这种问题的生成方式使估计所得解答的统计意义的任何一种机会不再存在。另外一方面,只有专业人员才能提出染色体选择的准则和有效地进行问题描述与生成。在系统中包含遗传算法的有美国的GeneHunter.
[8]非线性回归方法:这种方法的基础是,在预定的函数的基础上,寻找目标度量对其它多种变量的依赖关系。这种方法在金融市场或医疗诊断的应用场合,比较好的提供可信赖的结果。在俄罗斯的Paly Analyst以及美国的Neuroshell系统中包括了这种技术。
上面所列DM技术不可能是详尽的囊括,因为多年来数理统计分析以及AI与KE的研究提供了种类繁多特点各异的手段,DM开发人员完全可以根据不同任务加以选择使用,另外近年来在软计算(Soft Comp-uting)和不确定信息处理(dealing with Uncertainty of information)方法的研究,促使DM(KDD)技术向更深层次发展。
另外需要说明的,上面所说的DM中的数据是指数据库中表格形式中的记录和条目,这种数据称作结构型数据(Structured data)。在一个企业中,还有一类像文本和网页形式的数据,称作非结构型数据(unstructured data)。它来自不同的信息源,如文本 图像 影视和音响等,当然文本是最主要的一种非结构数据.对一个企事业单位来说,非结构型数据往往占数据总量的80%,而结构型数据只占20%。1995年分析家已预言,像文本这样非结构型数据将是在线存贮方面占支配地位的数据形式。到1998年初,在Internet上的信息网页数,已超过5亿,到2000年,预计网页数将达到15亿。随着Internet的扩展和大量在线文本的出现,将标志这巨大的非结构型数据海洋中,蕴藏着极其丰富的有用信息即知识。人们从书本中获取知识方法是阅读和理解。开发一种工具能不需要阅读而能协助用户从非结构数据中抽取关键概念以及快速而有效地检索到关心的信息,这将是一个非常引人入胜的研究领域。目前,基于图书索引检索以及超文本技术的各类搜索引擎,能协助用户寻找所需信息,但要深入发掘这类数据中的有用用信息,尚需要更高层次的技术支持,人工智能领域有关知识表示及获取的方法(如语义网络 概念映射等),和自然语言理解的研究成果,可望被采用。还可能要涉及到语言学 心理学等领域。最近已出现针对文本的DM工具的报导。如IBM公司的TexMiner,NetQuestion,WedCawler和megaputer公司的TextAnalyst等。
DM(KDD)工具和软件已在各个部门得到很好的应用,并收到明显的效益。[1]在对客户进行分析方面:银行信用卡和保险行业,用DM将市场分成有意义的群组和部门,从而协助市场经理和业务执行人员更好地集中于有促进作用的活动和设计新的市场运动。[2]在客户关系管理方面:DM能找出产品使用模式或协助了解客户行为,从而可以改进通道管理(如银行分支和ATM等)。又如正确时间销售(Right Time MarKeting)就是基于顾客生活周期模型来实施的。[3]在零售业方面:DM用于顾客购货篮的分析可以协助货架布置,促销活动时间,促销商品组合以及了解滞销和畅销商品状况等商业活动。[4]通过对一种厂家商品在各连锁店的市场共享分析,客户统计以及历史状况的分析,可以确定销售和广告业务的有效性。[5]在产品质量保证方面:DM协助管理大数量变量之间的相互作用,DM能自动发现出某些不正常的数据分布,暴露制造和装配操作过程中变化情况和各种因素,从而协助质量工程师很快地注意到问题发生范围和采取改正措施。[6]在远程通讯部门:基于DM的分析协助组织策略变更以适应外部世界的变化,确定市场变化模式以指导销售计划.在网络容量利用方面,DM能提供对客户组类服务使用的结构和模式的了解,从而指导容量计划人员对网络设施作出最佳投资决策。[7]在各个企事业部门,DM在假伪检测 及险评估 失误回避 资源分配 市场销售预测广告投资等很多方面,起着很重要作用。例如在化学及制药行业,将DM用于巨量生物信息可以发现新的有用化学成分.在遥感领域针对每天从卫星上及其它方面来的巨额数据,对气象预报,臭氧层监测等能起很大作用。总之,在国外,DM已广泛应用于银行金融,零售与批发 制造 保险 公共设施 政府 教育 远程通讯 软件开发 运输等各个企事业单位。据报导,DM的投资回报率有达400%甚至10倍的事例。
四 DM(KDD)产品状况
九十年代开始出现DM商用产品以来,据不完全统计,到1998年底1999年初,已达50多个厂商从事DM的开发工作,在美国DM产品市场在1994年约为5千万美元,1997年达到3亿美元。预计2000年将达到8亿美元。从产品的类型来分有下列产品:[1]提供广泛的DM能力,典型产品有IBM的Intelligent Miner,SAS的Enterprise Miner.[2]为某个部门旨在求解问题,典型的有Unica公司的Response Modeler Segnentor,IBM公司的Busiess Application等。[3]与提供服务一起,典型的有NeoVista,Hyperparallel,HNC Marksman.[4]黑匣工具,典型的有GroupModell,ModelMax,NewralWare的Predict.[5]解决客户问题有Marketier Paregram,Exchemge Application等。
DM商品软件一般包含多种技术方法,以适应不同要求。经常将成套工具按不同方式分成模块,例如Spss的DM套件由下列按功能的模块组成:[1]基于规则的影响发现模块。[2]多维共性发现模块。[3]OLAP发现模块。[4]增量发现模块。[5]趋向发现模块。[6]比较发现模块。[7]预测发现模块。而Neovista的DM套件却按所采用的技术分组,基于GA的DecisionGA和基于规则相关的DecisionAR.
由于DM不能只看作一个独立的操作,它是与前后操作联系起来,形成数据到知识的整体过程。有各种不同的组合方式,最自然的方式是将DM系统与数据仓库和常规的SQL用户界面和可视化工具联系在一起。如图5所示是NeoVista公司所提出的集成系统的示意简图。它是将集成化知识发现环境和开放式数据仓库组成一个DM的集成环境。为了使DM所得到的结果更广泛直接地为用户所用,人们提出了模式库(Patterm Base)模式仓库(Patterm Warehouse)加上联网模块的方案,如图6所示,这个称作DMsuite的结构直接工作在大型多表格的SQL数据库基础上,同时90%的DM工作在服务器上完成,这样就使DM工作不受客户机容量限制。
DM(KDD)的目的原本是为企事业单位提供决策的正确依据,从分析数据发现问题作出决策采取行动这一系列操作是一个单位的动作行为,利用计算机及信息技术完成这整体行动,是发挥机构活力和赢得竞争优势的唯一手段。所以前几年一位分析学家将这种机构行为和手段称这为“事务智能”(BI棗Business Intelligent).他认为BI能极大地改进决策的质量和及时性,从而改进机构的生产率或发挥竞争优势。所以近年来,一些大公司将数据分析和DM(KDD)工具和有关技术组合起来形成所谓BIS(Business Intelligent Softwave)。其中SAS公司的作法是将数据源 ,数据预处理 ,数据存贮 ,数据分析与发掘 ,信息表示与应用等方面技术有机地综合成一体。
IBM公司更全面地考虑BI系统的结构和功能,与其它公司共同合作来开发BI各类软件和工具。并从多方面来加以考虑:首先必须有一良好的数据库和数据仓库,并能使企业过渡到下一个世纪,所以提出了一个统一的数据库系统DB2和一个可视化数据仓库VDW(Visual Data Warehouse),可以将各种应用和各部门的信息融为一体,加上Visual Warehouse OLAP工具可以生成实时报告。在信息发现和数据发掘工具方面,提出能对结构型和非结构型数据进行发掘的一整套智能工具(Intelligent Miner Family)。BI手段只有在好的数据基础才能见效,因此提出数据重组工具。向用户提供联合统一观点的企业数据是作出聪明决策的前提,提出能支持异形数据库的DataJointer(数据接合)工具,具有简单而强有力的数据查询和优化的数据访问功能,并能对异形数据库数据进行复制,以便不断更新数据仓库内容。所有工具不仅易于使用外,并能与数据仓库无缝地集成在一起。图 8是IBM BI系统的结构图。BI系统标志着从数据到知识到决策的进程中的更深入的一步,展示着真正的实用的智能信息系统的雏形。有人将电子商务和BI看成90年代以来推动企业创新的两大重要技术,二者的结合可以提供指数增长的机遇。电子商务通过网络加速核心事务处理过程,改善对客户的服务,减少周期时间,从而从有限的资源中获得多的回报。而BI能利用丰富的数据资产做出最佳决策,以获取竞争优势。有人将两者的结合比做光速的飞行器加上精密的制导系统,能迅速而准确地命中目标。
五 结束语
本文从一个方面讨论从数据到知识的过程,以及计算机及信息技术在过程中的发展。新的世纪将是一个高度化信息化的时代,也就是知识时代,以知识为题的许多问题,诸如知识经济 知识产业 知识工人 知识管理 知识工程 知识网络等,将成为研究的对象。也势必推动以网络为环境的计算机与信息技术向更高层次发展。

 2007-10-23 23:04
2007-10-23 23:04