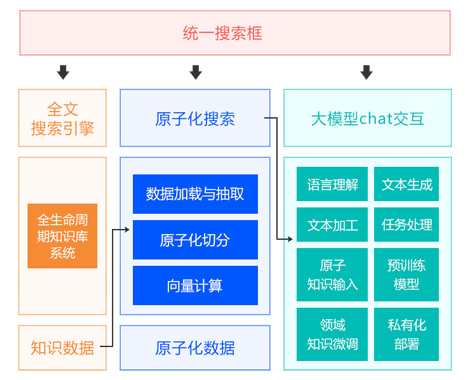
知识管理的基本XML和RDF技术(二) : 将文件合并到RDF模型和基本的RDF查询
Uche Ogbuji(
uche.ogbuji@fourthought.com)
首席顾问,Fourthought, Inc.
2001 年 9 月
这篇“Thinking XML”专栏文章演示了如何将从多个 XML
源文档中收集的元数据合并到用于有效查询的单个“资源描述框架”(Resource Description Frame (RDF))模型中。专栏作家 Uche
Ogbuji 在前一篇中介绍了如何一起使用 XML 和 RDF 来进行知识管理,本文是上一篇的继续,在本文中他论述了基于用从现有的 XML 格式获取的数据组成
RDF 模型的技术。该文的中心是一个示例,在该示例中,扩展基于 Web 的问题跟踪器(最初开发它来操纵 XML 格式的应用程序数据)来利用 RDF。XSLT 和
Python 样本代码清单演示了将来自 XML 文件的元数据聚合到单个 RDF 模型(一个使用 XSLT ,另一个使用 RDF)以及简单 RDF
查询的示例。
在本专栏的前一篇文章中,即知识管理的基本 XML 和 RDF
技术,第一部分(在继续阅读之前,可能需要重新回顾一下),介绍了一个基于收集的数据(以 XML 格式表示)的问题跟踪器应用程序示例。然后演示了如何使用 XSLT
从应用程序数据中抽取 RDF。
本专栏文章通过演示如何组合由转换每个 XML 源文档所创建的离散的 RDF
片段来完成这些事情。同时还演示了一些基本的查询技术。
资源批量派生
在上篇专栏文章中,完成了一个从 XML
源文件中抽取作为序列化格式的 RDF 的练习。然而,知识管理的大多数有用之处在于操纵 RDF 语句的抽象模型,而不是个别序列化文件。RDF
模型是图形结构,该结构可以非常简单也可以令人难以置信的复杂。(事实上,极端情况下,Semantic Web 的设想是要创建至少同当前 Web 一样大的 RDF
模型。如果实现该模型的话,它可能是曾经在使用中的最大的计算机数据结构。)
迄今为止,问题跟踪器的示例是由一组 XML 文件组成的,这些文件是 RDF
模型各部分的序列化。每一部分就象七巧板中的一块,如果将它们组合到一块儿,将表示问题跟踪器应用程序中所有数据的 RDF
模型。每一部分本身并不十分重要,因此下一步来讨论如何创建一幅完整的“图画”,该“图画”才是知识管理的真正价值所在。
使用 XSLT
进行批量转换
拼装该“图画”的一种选择是根本不处理七巧板块,而是使用 XSLT
一劳永逸地生成该“图画”。可以编写一个转换,该转换收集每个 XML 问题文档,并运用前一篇文章中所描述的 RDF 转换处理,然后将每次转换结果累积到一个序列化
RDF 结果。要做到这一点,需要利用标准的 document() XSLT 函数,该函数可以读入任意的文档,这些文档是作为用于转换的补充性 XML
源文档。
document() 函数需要知道所要读入文档的准确名称。XSLT
没有(比如说)通过使用通配符来读入多个文档的标准机制。可以通过许多方法解决这一问题(包括借助于 XSLT
扩展,该扩展允许通过通配符或其它机制来批量装入文档)。然而,因为这不是本示例的中心问题,所以选择创建带有每个问题文档清单的集中(hub) XSLT
文档这项折中方案。清单 1 issue-hub.xml 用指定的两个问题文档(在前一篇专栏文章中介绍过)来演示集中文档是什么样子的。
清单 1:带有每个应用程序数据文档的问题文档清单的集中 XML 文档。
issue1.xml
issue2.xml
一旦有了集中文档,就可以将清单 2 metadata-batch.xslt
中的转换应用到作为源文档的集中文档中以从所有列出的问题中创建聚合 RDF。
清单 2 看起来可能非常熟悉;其中大多数同前一篇文章中的转换相同。这是因为我很留意 XML
结构的模块化处理。根模板现在从集中文档中查找每个 issue 元素(注意,这里使用空名称空间)。然后它从每个元素内容中指定的文件名装入文档。注意,这里使用
document(.)/* 而不仅仅是
document(.)。这种构造防止处理器匹配问题文档的根节点,这会结束调用打算用于集中文档根节点的模板。那些正是本专栏文章的批量转换中的唯一区别。
可以使用任何 XSLT 处理器来执行该转换。我使用 4XSLT 来执行转换,如下所示:
$ 4xslt -o issues.rdf issue-hub.xml
metadata-batch.xslt
该转换导致 issues.rdf 中的序列化 RDF,它包含来自 issue1.xml 和 issue2.xml
中的元数据。
使用 RDF 工具进行批量转换
将多个 XML 文档聚合到单个 RDF
模型中的另一种选择是(如前一篇文章所述)分别构建每个 RDF 文档,然后使用 RDF
解析器将所有的文档解析成单个抽象模型。例如,通过对从前面一篇专栏文章中的示例问题文件中生成的两个 RDF 文件使用 4RDF,将得到清单
3。
清单 3:从 XML 文件中派生,并由 RDF 解析器(这里是 4RDF)分析的两个 RDF
问题文件的批量转换结果
$ 4rdf -d 1.rdf 2.rdf
The following is a list of resulting tuples, each in the form
"subject,
predicate, object".
[
("http://meta.rdfinference.org/ril/issue-tracker/ril-20010502",
"http://xmlns.rdfinference.org/ril/issue-tracker#issue",
"#i2001030423"),
("#anonymous:e08-e06-30b-90d-a060005104", "id",
"i2001030423"),
("#anonymous:e08-e06-30b-90d-a060005104",
"http://xmlns.rdfinference.org/ril/issue-tracker#author",
"http://users.rdfinference.org/ril/issue-tracker#uogbuji"),
("#anonymous:1040d07-20b-909-407-b0e0402205",
"http://xmlns.rdfinference.org/ril/issue-tracker#author", "Alexandre
Fayolle "),
("#anonymous:1040d07-20b-909-407-b0e0402205",
"http://xmlns.rdfinference.org/ril/issue-tracker#body", "The
abbreviation in listing 8 doesn't seem necessary to Nico Chauvat
or
me."),
("#anonymous:e08-e06-30b-90d-a060005104",
"http://xmlns.rdfinference.org/ril/issue-tracker#comment",
"#anonymous:1040d07-20b-909-407-b0e0402205"),
("#anonymous:60e0b06-50a-80c-90c-50a0a08602",
"http://xmlns.rdfinference.org/ril/issue-tracker#author",
"http://users.rdfinference.org/ril/issue-tracker#uogbuji"),
("#anonymous:60e0b06-50a-80c-90c-50a0a08602",
"http://xmlns.rdfinference.org/ril/issue-tracker#assignment",
"http://users.rdfinference.org/ril/issue-tracker#uogbuji"),
("#anonymous:e08-e06-30b-90d-a060005104",
"http://xmlns.rdfinference.org/ril/issue-tracker#action",
"#anonymous:60e0b06-50a-80c-90c-50a0a08602"),
("http://meta.rdfinference.org/ril/issue-tracker/ril-20010502",
"http://xmlns.rdfinference.org/ril/issue-tracker#issue",
"#i2001042003"),
("#anonymous:2030002-506-10a-201-f090809c08", "id",
"i2001042003"),
("#anonymous:2030002-506-10a-201-f090809c08",
"http://xmlns.rdfinference.org/ril/issue-tracker#author",
"http://users.rdfinference.org/ril/issue-tracker#nchauvat"),
("#anonymous:c000706-b0b-d02-d0a-e050c0460b",
"http://xmlns.rdfinference.org/ril/issue-tracker#author", "Alexandre
Fayolle "),
("#anonymous:c000706-b0b-d02-d0a-e050c0460b",
"http://xmlns.rdfinference.org/ril/issue-tracker#body", "I agree"),
("#anonymous:2030002-506-10a-201-f090809c08",
"http://xmlns.rdfinference.org/ril/issue-tracker#comment",
"#anonymous:c000706-b0b-d02-d0a-e050c0460b"),
("#anonymous:b0c0c00-800-2-c08-20a0d0f209",
"http://xmlns.rdfinference.org/ril/issue-tracker#author",
"http://users.rdfinference.org/ril/issue-tracker#uogbuji"),
("#anonymous:b0c0c00-800-2-c08-20a0d0f209",
"http://xmlns.rdfinference.org/ril/issue-tracker#assignment",
"http://users.rdfinference.org/ril/issue-tracker#uogbuji"),
("#anonymous:2030002-506-10a-201-f090809c08",
"http://xmlns.rdfinference.org/ril/issue-tracker#action",
"#anonymous:b0c0c00-800-2-c08-20a0d0f209"),
]
清单 3 中第一行里的 -d 选项告诉 $RDF 将 subject/predicate/object 三元组从抽象 RDF
模型转储到命令行,该命令行显示清单 3 的剩余部分.
一旦有了问题跟踪器的完整 RDF 模型,可能希望以一种更易于阅读的格式而不是清单 3
中所显示的那种格式来查看它。例如,如果以清单 3 中的聚合 RDF 文件为例,并使用 Dan Brickley 的 RDF
可视化工具(请参阅参考资料)来处理它。
可以立即辨别出某种模式,譬如用户“uogbuji”的投稿和职责。当然,我必须承认 RDF 中随同 URI
而来的冗长的标识符妨碍了这一清晰性。
跨系统查询
拥有可用元数据的 RDF
模型的另外一个立杆见影的好处在于:它使许多系统级查询(相对于编写针对一组 XML 文档的 XPath
查询,或将数据集中到专用数据结构以用于查询)变得更简单更一般。虽然,“XML 查询语言”(XQuery)和 XML
资源库供应商提供的专用文档收集查询工具的出现也帮助解决了这一需求,但是现在可以使用 RDF,至少这种基本模型是标准化的。
遗憾的是,RDF 模型的查询还不是标准化的,这是 RDF 社区需要填补的非常重要的漏洞。幸运的是,由于 RDF
模型的简单性,所以非常容易通过基本模式匹配来构建几乎所有形式的查询。这是 4RDF
中所使用的基本方法,其中,查询就是就是查找语句三元组的过程,该三元组匹配给定的主语、谓语和宾语模式。作为示例,请看表 1
中刚创建的部分统一模型。
表 1 .来自问题跟踪器数据的一些语句
| 主语: |
#anonymous:a0d010d-f0c-706-20e-80a0407606 |
| 谓语: |
http://xmlns.rdfinference.org/ril/issue-tracker#body |
| 宾语: |
Organize a vote on this topic |
|
| 主语: |
#anonymous:a0d010d-f0c-706-20e-80a0407606 |
| 谓语: |
http://xmlns.rdfinference.org/ril/issue-tracker#assign-to |
| 宾语: |
http://users.rdfinference.org/ril/issue-tracker#uogbuji |
|
| 主语: |
#anonymous:402000d-403-309-c01-9080a205 |
| 谓语: |
http://xmlns.rdfinference.org/ril/issue-tracker#body |
| 宾语: |
Correct all to use the "0/1" form in the next
draft. |
|
| 主语: |
#anonymous:402000d-403-309-c01-9080a205 |
| 谓语: |
http://xmlns.rdfinference.org/ril/issue-tracker#assign-to |
| 宾语: |
http://users.rdfinference.org/ril/issue-tracker#uogbuji |
有了这些三元组,就会非常容易地明白别人是如何会简单地询问如下问题:“给用户 uogbuji
分配的操作标识是什么?”以及“每个操作的主体是什么?”。将第一个问题转换成查找匹配下列模式的三元组,这里的“*”是匹配任何值的通配符:
对此的响应之一是带有主语“#anonymous:a0d010d-f0c-706-20e-80a0407606”(表示匹配的操作标识)的语句。注意,该标识是由
4RDF
为匿名资源(如果资源没有标识,则由应用程序显式地分配一个)生成的特殊标识。构成全球唯一标识符(UUID)的一个十六进制值紧跟在“anonymous”序列之后。有了这个标识,第二个示例问题相当于匹配下列模式,该模式返回带有宾语“Organize
a vote on this topic”的语句:
| 主语 |
谓语 |
宾语 |
| #anonymous:a0d010d-f0c-706-20e-80a0407606 |
http://xmlns.rdfinference.org/ril/issue-tracker#body |
* |
建立在这一简单的想法上,几乎任何形式的 RDF
查询(甚至关系型(SQL)查询和对象(OQL)查询的等价查询)都是可能的。
编码 RDF 查询
清单 4 中的 Python 程序 query1.py 通过模式匹配、读入 issues.rdf
文件以及打印 uogbuji 的所有任务的主体,使用 4RDF 来运用这项查询技术。(如果没有使用 Python,当然可以使用其它 RDF 查询工具,譬如
RDFDb、Jena 或列在参考资料中“Dave Beckett 的 RDF 资源指南”中的工具。)
清单 4:演示一个 RDF 模型简单查询的 Python 程序。
from Ft.Rdf import Util
#Returns an RDF model object, and the database instance it uses
for
#persistence (in our case, it's just a memory data
structure)
model, db = Util.DeserializeFromUri('issues.rdf')
db.begin()
USER_ID_BASE =
'http://users.rdfinference.org/ril/issue-tracker#'
IT_SCHEMA_BASE =
'http://xmlns.rdfinference.org/ril/issue-tracker#'
print 'Actions assigned to uogbuji:'
#None is used as the wild-card
matching_statements = model.complete(None,
IT_SCHEMA_BASE+'assign-to',
USER_ID_BASE+'uogbuji'
)
for statement in matching_statements:
id = statement.subject
matching_statements = model.complete(id,
IT_SCHEMA_BASE+'body',
None
)
body = matching_statements[0].object
print "*", body
db.commit()
在清单 4 中,首先从 issues.rdf 文件中读取(解除序列化)RDF;然后执行查询以查找表示指派给 uogbuji
哪些操作的语句。然后使用每个语句的主语(操作标识)来查询每个操作的主体。如果安装了 Python 和 4Suite,运行和下面相同的示例:
$ python query1.py
Actions assigned to uogbuji
* Organize a vote on this topic
* Correct all to use the "0/1" form in the next
draft.
这是 RDF 模型查询的最底级别,因此有一点麻烦。清单 5 中的 Python 程序 query2.py
通过直接查询相关主语和宾语等而走了一些捷径。其结果就是清单 4 中同一个功能的更简单的版本。
清单 5:简化查询代码
from Ft.Rdf import Util
#Returns an RDF model object, and the database instance it uses
for
#persistence (in our case, it's just a memory data
structure)
model, db = Util.DeserializeFromUri('issues.rdf')
db.begin()
USER_ID_BASE =
'http://users.rdfinference.org/ril/issue-tracker#'
IT_SCHEMA_BASE =
'http://xmlns.rdfinference.org/ril/issue-tracker#'
print 'Actions assigned to uogbuji:'
actions = Util.GetSubjects(model,
IT_SCHEMA_BASE+'assign-to',
USER_ID_BASE+'uogbuji')
for action in actions:
body = Util.GetObject(model, action,
IT_SCHEMA_BASE+'body')
print "*", body
db.commit()
清单 5 仍然包含两种级别的查询;使用结合多个查询的单个请求将更方便和更有效。(通过使用“RDF 推论语言(RDF
Inference Language (RIL))”,那也是可能的,“RDF 推论语言”将在本专栏的后续文章中讨论。顺便提一下,示例问题跟踪器数据中参考了
RIL 开放规范草稿。)清单 6 演示了在使用或不使用 API 捷径情况下,执行基本查询的结果。
清单 6:执行同清单 5 相同任务的简化的查询会话
$ python query2.py
Actions assigned to uogbuji
* Organize a vote on this topic
* Correct all to use the "0/1" form in the next
draft.
RDF 查询不必涉及元数据语句组件的精确匹配。大多数的查询语言提供大量的灵活性。作为一个示例,清单 7(query3.py)中的
Python 程序使用基于正则表达式的查询来查找所有指派给 uogbuji 的操作(该操作的主体包含字符串“vote”)。
同样,通过使用 RIL,清单 7 中的代码将是一个简单查询而且更有效(将在下一篇专栏文章里讲述)。清单 8
演示了查询中正则表达式的使用。
清单 8:演示在查询中使用正则表达式的会话
$ python query3.py
Actions assigned to uogbuji
* Organize a vote on this topic
下一次……
本专栏文章演示了如何从示例问题跟踪器应用程序将各部分组成完整的
RDF 模型,并且举例说明了该模型的基本查询。在下篇文章中将探讨一种丰富特性,可以利用 RDF 的强大功能来低成本地利用该特性。
参考资料
通过单击文章顶部或底部的讨论来参与本文的讨论论坛。
请下载作者上一篇专栏文章中样本代码(介绍了使用 XML
的 RDF 技术)和本专栏中样本代码文件的压缩文件,这些文件使得理解这些示例或修改它们以利于重用变得更加容易。
Uche Ogbuji 的 Introduction
to RDF 提供了对 RDF 的基本介绍,并包含指向其它有用资源的链接。
Dave Beckett 的 RDF 资源指南 是一个指向与
RDF 相关文章、
工具、规范、讨论和事件等等的综合性的链接集。
Dan Brickley 的 RDF
可视化器(是基于 Web 的,并且可以应用到任何平台)象本专栏文章中的图 1 一样,以图形形式表示 RDF 文件。
本文中提及过但没有演示过的两个 RDF 查询工具是与 RDF 数据库 RDFDb 相关联的查询语言(其提供了用 C 与 Perl 来访问数据库)和 Jena(用于操纵 RDF 模型的实验性
Java API)。
使用 4Suite 的 XSLT 处理器测试了本文中的示例。
XML:the
next big thing,是由 Tom Halfhill 所写的学术性 IBM 研究论文,它讨论了使用 RDF 增强下一代搜索引擎的可能性。
请参阅本专栏以前的专题,题为:
正如 Scientific
American article 中所描述的那样,Semantic Web 正在逐渐成为人们所研究和感兴趣的事物,并且现在是 W3C 官方活动
浏览:知识管理的基本XML和RDF技术(一)
知识管理的基本XML和RDF技术(三)
知识管理的基本XML和RDF技术(四)
知识管理的基本XML和RDF 技术(五)
知识管理的基本XML和RDF技术(六)

 2002-08-21 10:17
2002-08-21 10:17