- 首页
- 知识管理
-
知识智能
-
知识智能产品
-
-
在知识库中,仅仅通过数据库检索,全文搜索,往往会出现搜索不到、搜索不准的情况。
深蓝海域运用人工智能技术,探索搜索引擎的智能化,让用户搜索知识变动更简单 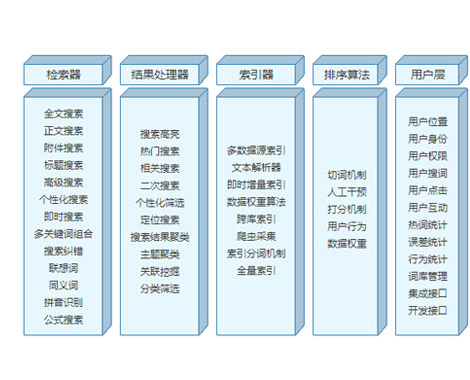
-
如果您每天花大量的时间在指定的网站上查找各类知识信息,作为研究、内参,如果您正在苦恼这些信息需要人工下载,需要人工辨别分类,需要人工去重,去干扰,那您一定不能错过“包打听”。
基于爬虫和机器学习技术打造,自动采集、自动去重归类、个性化分发推荐、知识关联挖掘,只为您打听您想了解的内容! 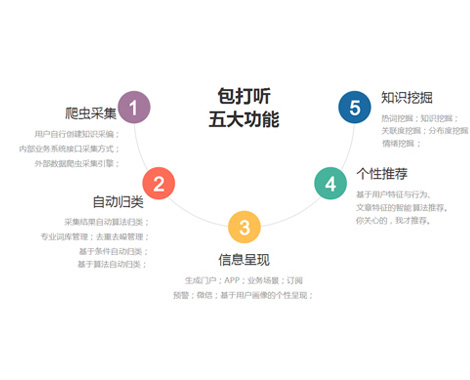
-
工单系统中具有海量数据的工单信息,通过构建和训练“工单知识萃取模型”,萃取出有效的工单知识,将其应用于工单的提出、处置等环节,从而减少重复工单的提出率、提升工单处置效率和解决准确率

-
健康险理赔是一个专业、复杂的过程,需要医药和保险双重领域的知识辅助。
深蓝基于知识规则引擎,研发了“药-病-症”知识规则库,可以从“对症用药”、“合理用药”两个方面,对健康险理赔提供智能支持服务。 
-
传统的知识库只能进行全文搜索,查出结果一堆。传统的客服问答机器人呢?需要人工根据文档整理大量的QA问答对儿,超级反人类。
有没有一种可能,只需提出你的问题,系统从知识库中自动找到对应的文章,并从文章中截取最相关的一段作为答案发送给你?这就是“智能知识助手”! 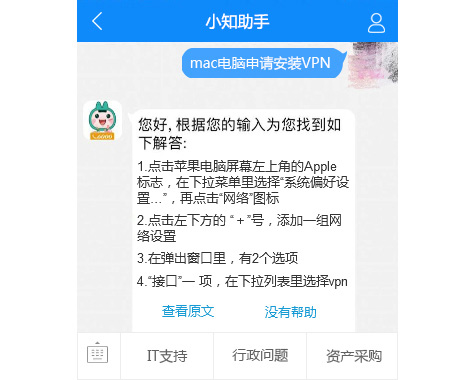
-
信息太多,数据太多,知识库内容太多!还在人工的进行分类,建立知识地图吗?
快来试试基于多条件组合、基于机器学习模型的自动归类引擎,轻松将千万文档、资料合理归类! 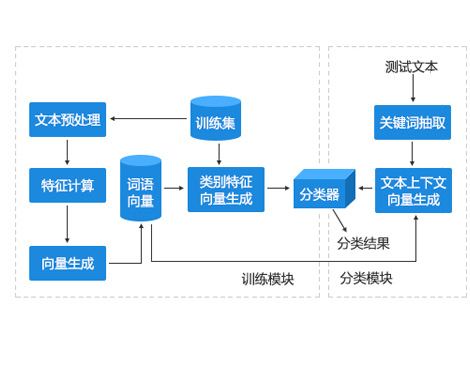
-
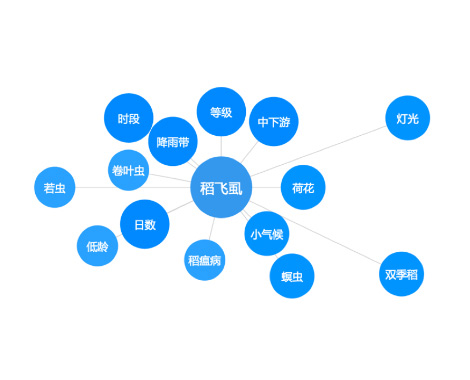
怎样从海量数据中发现未知的规律,找寻到热点、问题,时间和地理分布,关联人、事件等,基于非结构化文本的知识挖掘引擎,轻松知识挖掘,提供图表化的决策支持依据。
-
-
- 咨询服务
- 行业案例
- 产品理念
- KM百科
- 关于深蓝
 2008-03-10 12:08
2008-03-10 12:08